Tables for presenting results from regression analyses¶
When you have conducted a statistical analysis it is important to present the results in a clear and pedagogical way. Most of the time, this means a combination of text, tables and graphics. The aim is to present enough information that the reader can grasp the most important conclusions, and see how they were reached, without burdening the reader with too much information. This is especially relevant for numbers that are not interpreted or commented upon in the text.
The normal output Stata produces after a regression analysis is not suitable for publication. You can pick out the most important numbers and do your own table in Word, for instance, but there are easier ways, with special commands in Stata.
One such command is esttab. In this guide we will discuss how to use it to produce a simple but nice regression table. But first we need to install esttab, since it is not preinstalled with Stata. We do this by writing the following (and we only need to do this once):
ssc install estout, replace
Then we load the data. In this example we will use the QoG Basic data, version 2018. You can download it to your computer and open it from there, or connect to it directly, which I'm doing here.
use "https://www.qogdata.pol.gu.se/dataarchive/qog_bas_cs_jan18.dta", clear
Hypothesis: Democracy increases life expectancy¶
The units of analysis are countries. We are going to do a simple analysis where we investigate the possible relationship between democracy and life expectancy. Do people live longer in democracies? And if so, does that relationship hold under control for other variables, for instance geographic location? Some theories say that democracies had more fertile soil in more temperate climates, far away from the equator. And in those locations, there are fewer tropical diseases (which decrease life expectancy).
If democracy really is good for health, we should find a relationship between democracy and life expectancy, even under control for geographical location.
The variables we will use are:
Life expectancy: wdi_lifexp
Degree of democracy: p_polity2 (-10 till -10)
Distance from the equator: lp_lat_abst
Below we see descriptive statistics for the three variables.
sum wdi_lifexp p_polity2 lp_lat_abst
Store the results from regression analyses with estimates store¶
We will run three regression analyses. First with democracy as independent variable, then with distance from the equator, and then with borth democracy and distance from the equator. After each analysis, we write estimates store m1 where m1 is the name of a model (which we choose ourselves). I usually name the models m1, m2, m3 and so forth. In the block of code below, I run the analyses and store the results.
reg wdi_lifexp p_polity2
estimates store m1
reg wdi_lifexp lp_lat_abst
estimates store m2
reg wdi_lifexp p_polity2 lp_lat_abst
estimates store m3
Present the results with esttab¶
The regression output is obviously very clunky, and contains a lot of information that we generally are uninterested in. For instance, the standard errors, t-values, p-values and confidence intervals all express roughly the same thing: the degree of uncertainty around the estimate of the b-coefficient. We don't need to show them all. Common in the social sciences is that you show the coefficient, the standard error (or the t-value) and place stars that show the significance level (the p-value).
esttab does a lot of this automatically. To do a minimal table of the three analyses we have stored we only have to write:
esttab m1 m2 m3
Much better! Each column represents one analysis - a "model." At the top we have what was the dependent variable in the analysis. The numbers represent the b-coefficients for each variable. In the parentheses are the t-values, and at the bottom we have the n, the number of observations.
We can see that in the first model, there was a significant relationship between democracy and life expectancy - each step up on the democracy scale is associated with an increase of life expectancy of 0.394 years. But we also see, in model 2, that countries that are further away from the equator have higher life expectancy. And we know (even though it is not evident from the table) that countries further away from the equator are more democratic. So when we control for the distance to the equator, in model 3, the coefficient for democracy is more than halved, to 0.155, and it is no longer significiant (as there are no stars next to the coefficient, and the t-value is below 1.96).
But there are other things we would like to see in the table, for instance the R2-value, or adjusted R2. And we might be more interested in the standard error, rather than the t-value. Then we can add options to our command. You choose yourself what you want. Use help esttab to see the complete list of options.
esttab m1 m2 m3, se r2 ar2
This table is easy to overlook and read. The only problem is that it is not easily transferred to a Word document. If you do, you have to set the font to Courier or something else where all the letters have equal size, or all numbers will end up in the wrong places.
But a better way is to export the table to a separate file that is adapted to Word, for instance. Then you can open the file and copy the table from there to your own report.
To export the file we add using "filename.rtf" in the code. The file will then be saved in the active folder. You pick the active folder by writing cd "Users/mycomputer/statisticalanalysis/" for instance. I also add replace as an option, which means that if there is already a file with this name, it will be replaced.
esttab m1 m2 m3 using "regressiontabell.rtf", se r2 ar2 replace
If you then open the file with Word it will look like this:
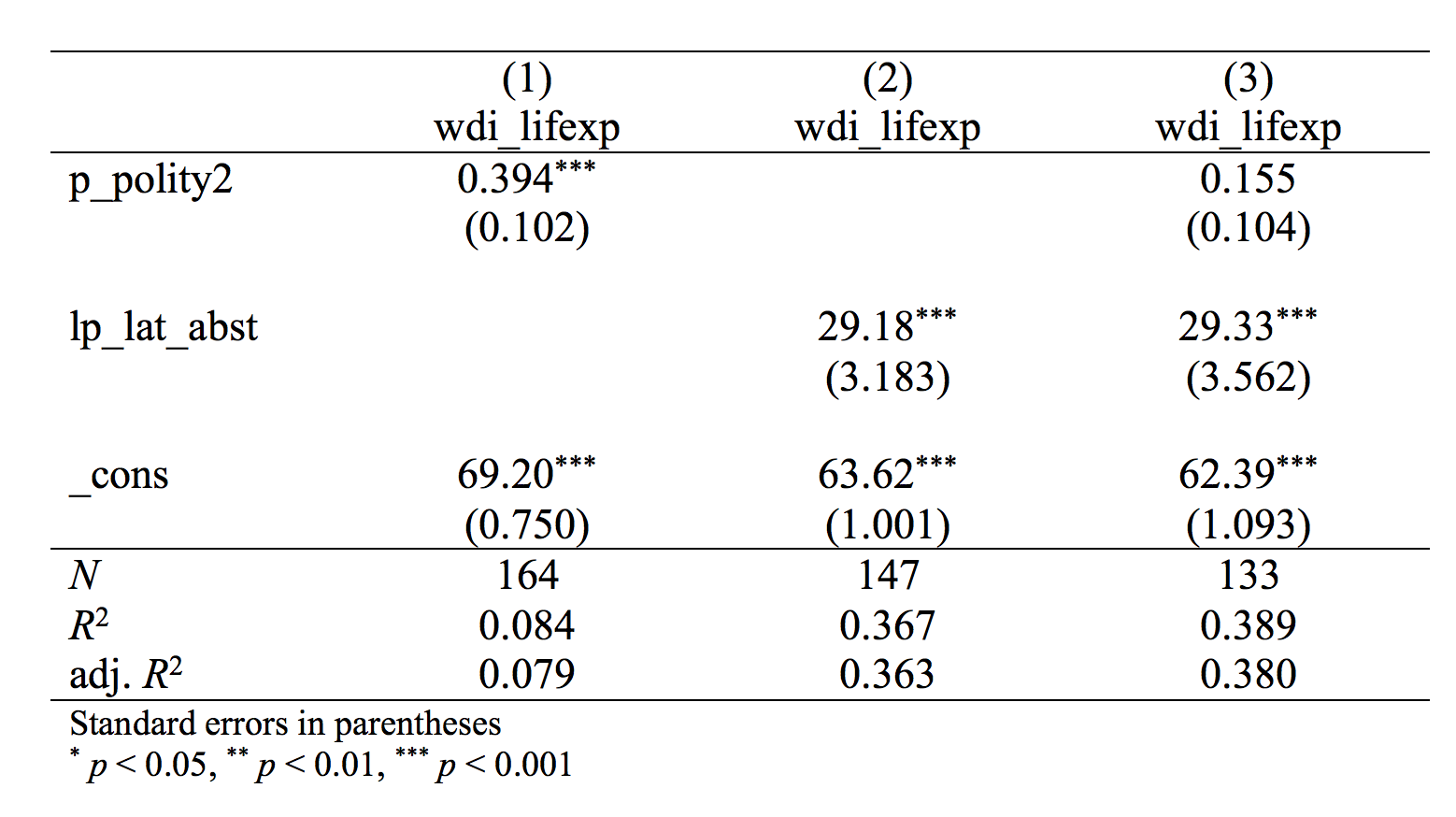
You can then of course make the table even more pedagogical by replacing the variable names to more explanatory labels, for instance "Democracy (-10 to +10)" or something similar. but thist able is still a big improvement compared to the raw output.
Conclusion¶
To do tables with esttab thus requires three steps. First you do the analysis, then you save the results from it with estimates store and then you present the results with esttab.
Remember to always be clear and as pedagogical as possible. The person with the most to lose from the reader not understanding your results is you!