Getting started with Stata¶
by Anders Sundell
Stata is a program for data management and statistical analysis that is used frequently within the scientific community. The program has different parts.
The data files, "dataset," store the actual data we analyze, and have the file ending .dta. We can also load data in other formats, such as comma separated text files, .csv files.
The do-files are text files with code, that is, commands to the program. The files have the file ending .do and are stored separately. We can also type commands directly into Stata, or point and click in menus, but it is less transparent, and increases the risk of error.
A good workflow is instead to create a do-file for each project. In the do-file, we:
- State the address to the folder where we keep our data files,
- Load the data files, do appropriate recodings and trim the data before the analyses that we are planning
- Run the analyses
- Produce tables and graphs that can be used in tet documents or presented on the web.
All data work is thus described in the do-file, and no changes are saved in the original dataset. This means, that when we close Stata and a window asks us if we want to save changes to the DATASET, we say no. This way, the work is easy to share with others, and we reduce the risk of errors that cannot be traced.
The picture shows how it can look like when we work in Stata. The do-file is open in a separate window.
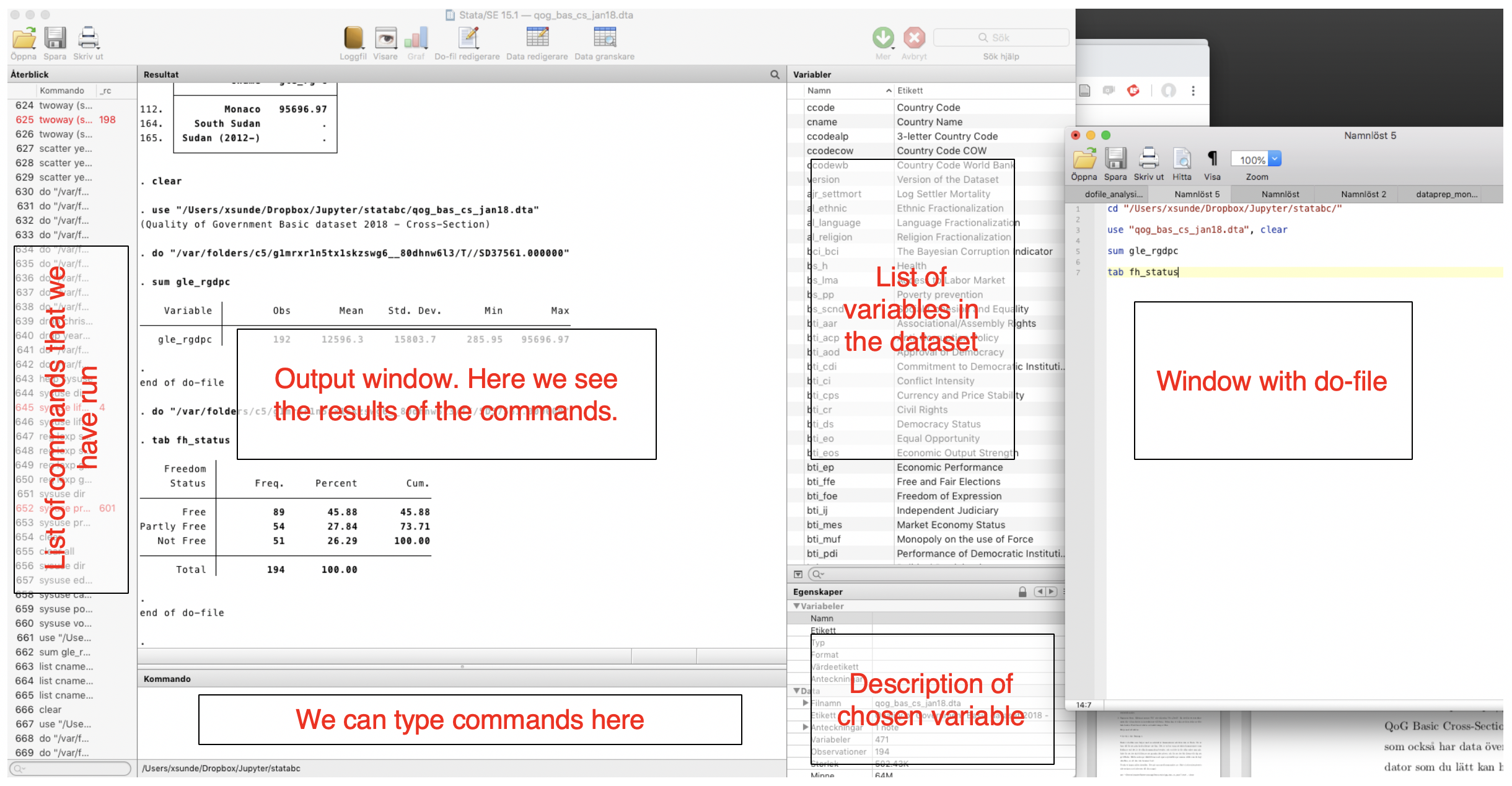
Set address of project folder¶
It is good practice to start the do-file with the address to the folder where we keep our project. Stat will then understand that we are "in" that folder, will open files from that folder, and will also save tables and graphs to the same folder.
On PC we see the address in the address field of the folder. It might look something like this: "C:/Users/anders/Desktop/Statistik/".
On Macs we can right-click (or ctrl+click) on a file in our folder, and then "show info". We can then copy the address on "Location". It might look something like this: "/Users/anders/Desktop/Statistik".
In the do-file we then enter the address of the folder where we want to keep our project:
cd "/Users/xsunde/Dropbox/Jupyter/stathelp"
To run the command, we select it in the do-file and press the button "Do" in the top right corner, or use the keyboard shortcut. On PC it is ctrl+D, on Mac cmd+shift+D.
Load a dataset¶
We then open our data file, with the use command. A good idea is to save the .dta file we want to use in our project folder. If we have done that, we don't need to state the full address in the command, which we must do if the data is located somewhere else. This is what it looks like when we load the QoG basic dataset (which was saved in the folder):
use "qog_bas_cs_jan18.dta", clear
The command is always first, in this case it is use. Then follows the name of the dataset in this case, but with most other commands we instead type in the name of the variables that we want to analyze or recode.
The comma after the file name is an indicator that a new part of the command is starting, namely the "options." Such are available for all commands, and help finetune them. In this case it only says clear, which means that we want to empty Stata of everything else that is loaded in the program before we load the new dataset. Stata will not let us open a new dataset if we have another dataset open, unless we give the option clear.
A good workflow¶
We can then proceed with doing the recodings and the analyses we have planned. A good idea is to, in the do-file, place the data management stuff after opening the dataset, but before the analyses. This way, we can run the complete dofile from the top to the bottom everytime we work with the project.
The idea is thus that when we work on the project, we do changes in the do-file which we save. The do-file is thus updated continously. But the actual dataset is only changed temporarily. Everytime we work with the project, the dataset is opened, changed in a lot of ways, depending on the requirements of the analyses. But when we are done with the analyses, we shut down the program without saving the changes in the data - only the changes in the do-file are saved.
One of the reasons is that we often change variables. For instance, we might want to divide an age variable into two groups, those that are over and under 50 years. If we later decide that it would be better to divide the varible into over and under 40, we would have lost the original information if we had saved the changes to the actual data.
If we instead work with do-files we will always have the original data, and we can simply change the commands in the do-file, so that the line is drawn at 40 instead of 50. This makes the workflow more transparent. Apart from being a benefit for the researcher doing the analysis and colleagues in the project, most reputable scientific journals nowadays require that those who want to publish in the journal submit their code, so that reviewers can inspect the analyses and the data management.