Komma igång med Stata¶
av Anders Sundell
Stata är ett program för datahantering och statistisk analys som används flitigt inom forskarsamhället. Grundupplägget är att programmet har olika delar.
Datafilerna, "dataset", innehåller själva datan som vi analyserar, och har filändelsen .dta. Men man kan också ladda in till exempel kommaseparerade .csv-filer.
Do-filerna är textfiler med syntax, alltså kommandon till programmet. Filerna har ändelsen .do och sparas separat. Man kan även skriva in kommandon direkt i programmet, eller peka och klicka i menyer, men det är mindre transparent och ökar risken för slarvfel.
Ett lämpligt arbetsupplägg är istället att man gör en do-fil för varje projekt. I do-filen anger man sökvägen till mappen där man har sina datafiler, laddar in datafilerna, gör lämpliga omkodningar och snyggar till datan inför de analyser man planerar, genomför analyserna, och producerar tabeller och grafer som sedan kan föras in i textdokument eller presenteras på webben till exempel. Det vill säga, allt data-arbete finns beskrivet i do-filen, och inga ändringar sparas i det ursprungliga datasetet. På så vis är det lätt att dela med sig av sitt arbete till andra, och man minskar risken för fel.
I bilden nedan visas hur det ser ut när man jobbar i Stata. Do-filen är öppen i ett separat fönster.
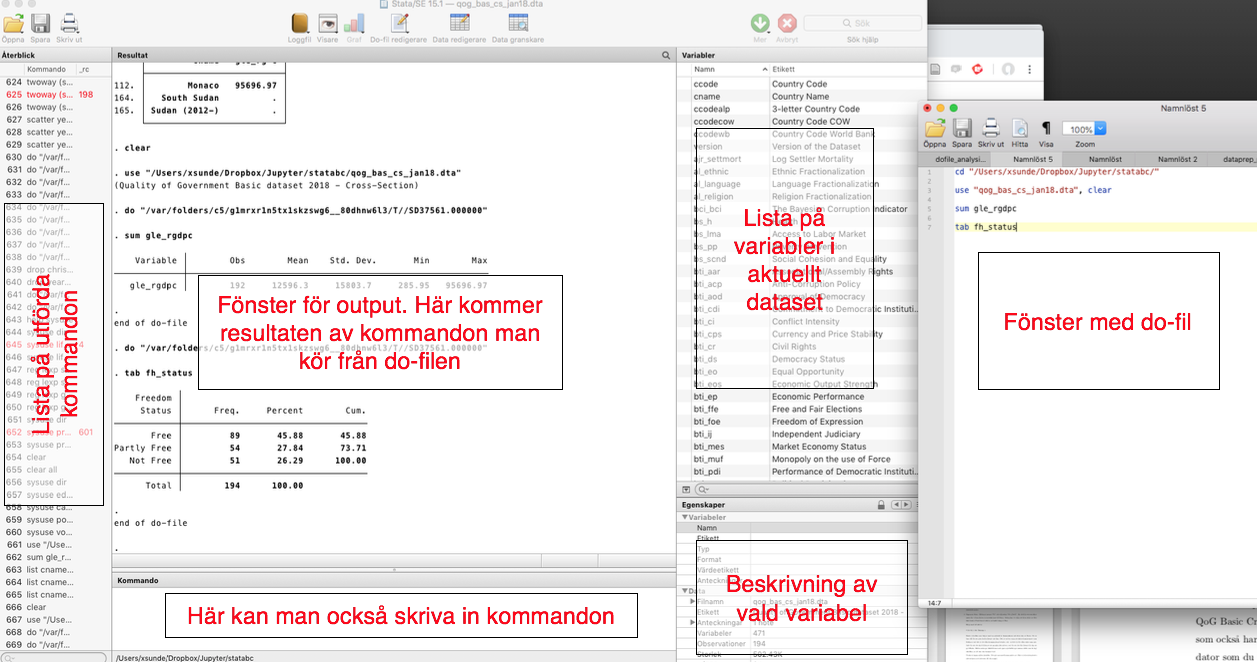
Ange sökväg till projektmappen¶
Det är bra att i sin do-fil börja med att ange sökvägen till mappen där man har sitt projekt. Då förstår Stata att vi är "i" den mappen, och kommer öppna filer därifrån, och också spara tabeller och grafer till samma mapp.
På PC ser man i utforskaren sökvägen i mappens adressfält. Den kanske ser ut ungefär såhär: "C:/Users/anders/Desktop/Statistik/". På Mac kan man högerklicka på en fil i sin mapp, och sedan trycka på "visa info". Då kan man sedan kopiera det som står på "plats. Det kanske ser ut ungefär såhär: "/Users/anders/Desktop/Statistik".
I do-filen skriver man sedan in adressen till mappen där man vill ha sitt projekt:
cd "/Users/xsunde/Dropbox/Jupyter/statabc"
För att köra kommandot markerar man det vill köra i do-filen och trycker på knappen "Do" uppe i högra hörnet, eller använder tangentbordsgenvägen. På Mac är det cmd+shift+D.
Öppna datamängden¶
Sedan öppnar man sin datafil, med use-kommandot. Lämpligen har man lagt .dta-filen man vill använda i sin projektmapp. Då behöver man inte ange någon speciell sökväg. Ligger datan någon annanstans på datorn får man skriva in den fullständiga sökvägen. Såhär ser det ut när man öppnar QoG basic-datamängden:
use "qog_bas_cs_jan18.dta", clear
Kommandot skrivs alltid först, i det här fallet "use". Sen följer i det här fallet sökvägen till filen vi vill öppna. Hade det varit ett annat kommando hade vi kanske istället skrivit in några variabler vi ville analysera.
Kommatecknet som kommer efter sökvägen indikerar att en ny del av kommandot börjar, nämligen "options". Sådana finns för alla kommandon, och är fininställningar till kommandot. I det här fallet står det bara "clear", vilket betyder att vi vill rensa ut allt som är inladdat i programmet innan vi laddar in den nya datamängden. Har man en annan datamängd öppen låter Stata en inte öppna den nya, om man inte har angett "clear".
En bra arbetsstruktur¶
Sen är det bara att fortsätta med den datahantering och de analyser man vill göra. Det är smart att i sin do-fil lägga datahanteringen efter att man öppnat datamängden, men före analyserna. På så vis kan man köra hela do-filen uppifrån och ner varje gång man ska arbeta med projektet.
Tanken är alltså att man när man jobbar gör förändringar i do-filen som man sparar. Do-filen uppdateras alltså kontinuerligt. Men själva datamängden ändras bara temporärt. Varje gång man arbetar med projektet öppnas datafilen, och ändras sen på olika sätt, utefter analysernas behov. Men när man när är färdig med sina analyser stänger man programmet utan att spara förändringarna i datan, bara do-filens förändringar sparas.
Anledning är att man ibland gör förändringar av variabler. Säg att man till exempel vill dela in en variabel för ålder i två grupper, de som är över respektive under 50 år. Om man senare kommer på att det är bättre att dela in det i över och under 40 har man tappat den ursprungliga informationen, om man sparat förändringarna i datamängden.
Om man arbetar med do-filer så finns ursprungsdatan hela tiden kvar, och det är bara att ändra i kommandot i do-filen, så att gränsen går vid 40 istället för 50. Och som sagt tidigare gör det också arbetsprocessen mer transparent. Nuförtiden kräver de flesta vetenskapliga tidskrifter att man tillhandahåller sin kod, så att granskare kan se hur analyserna och datahanteringen gått till.